我本想写一篇关于 DeepSeek R1 的科普文,但发现很多人仅仅把它理解为 OpenAI 的复制品,而忽略了它在论文中揭示的"惊人一跃",所以,我决定重新写一篇,讲讲从 AlphaGo 到 ChatGPT,再到最近的 DeepSeek R1 底层原理的突破,以及为什么它对所谓的 AGI/ASI 很重要。作为一名普通的 AI 算法工程师,我可能无法做到非常深入,如有错误欢迎指出。
AlphaGo 突破人类上限
1997 年,IBM 公司开发的国际象棋 AI 深蓝,击败了世界冠军卡斯帕罗夫而引发轰动;接近二十年后的 2016 年,由 DeepMind 开发的围棋 AI AlphaGo 击败了围棋世界冠军李世石,再次引发轰动。
表面上看这两个 AI 都是在棋盘上击败了最强的人类棋手,但它们对人类的意义完全不同。国际象棋的棋盘只有 64 个格子,而围棋的棋盘有 19x19 个格子,假如我们用一盘棋能有多少种下法(状态空间)来衡量复杂度,那么二者对比如下:
- 理论上的状态空间
- 国际象棋:每局约 80 步,每步有 35 种走法 → 理论状态空间为 $35^{80} \approx 10^{123}$
- 围棋:每局约 150 步,每步有 250 种走法 → 理论状态空间为 $250^{150} \approx 10^{360}$
- 规则约束后的实际状态空间
- 国际象棋:棋子移动受限(如兵不能倒退、王车易位规则) → 实际值 $10^{47}$
- 围棋:棋子不可移动且依赖"气"的判定 → 实际值 $10^{170}$
| 维度 |
国际象棋(深蓝) |
围棋(AlphaGo) |
| 棋盘大小 |
8×8(64 格) |
19×19(361 点) |
| 平均每步合法走法 |
35 种 |
250 种 |
| 平均对局步数 |
80 步/局 |
150 步/局 |
| 状态空间复杂度 |
$10^{47}$ 种可能局面 |
$10^{170}$ 种可能局面 |
▲ 国际象棋和围棋的复杂度对比
尽管规则大幅压缩了复杂度,围棋的实际状态空间仍是国际象棋的 $10^{123}$ 倍,这是一个巨大的量级差异,要知道,宇宙中的所有原子数量大约是 $10^{78}$ 个。在$10^{47}$范围内的计算,依赖 IBM 计算机可以暴力搜索计算出所有可能的走法,所以严格意义上来讲,深蓝的突破和神经网络、模型没有一点关系,它只是基于规则的暴力搜索,相当于一个比人类快得多的计算器。
但$10^{170}$的量级,已经远远超出了当前超级计算机的算力,这迫使 AlphaGo 放弃暴力搜索,转而依赖深度学习:DeepMind 团队用人类棋谱训练神经网络,引入蒙特卡洛树搜索(MCTS)算法,从而极大地压缩每一步的搜索空间,让模型能根据当前棋盘状态预测下一步棋的最佳走法。但是,学习顶尖棋手走法,只能让模型的能力接近顶尖棋手,而无法超越他们。
AlphaGo 首先用人类棋谱训练模型,然后通过设计一套奖励函数,让模型自我对弈进行强化学习。和李世石对弈的第二局,AlphaGo 的第 19 手棋(第 37 步)让李世石陷入长考,这步棋也被很多棋手认为是"人类永远不会下的一步",如果没有强化学习和自我对弈,只是学习过人类棋谱,AlphaGo 永远无法下出这步棋。
2017 年 5 月,AlphaGo 以 3:0 击败了柯洁,DeepMind 团队称,有一个比它更强的模型还没出战。 他们发现,其实根本不需要给 AI 喂人类高手的对局棋谱,只要告诉它围棋的基本规则,让模型自我对弈,赢了就奖励、输了就惩罚,模型就能很快从零开始学会围棋并超越人类,研究人员把这个模型称为 AlphaZero,因为它不需要任何人类知识。
让我再重复一遍这个不可思议的事实:无需任何人类棋局作为训练数据,仅靠自我对弈,模型就能学会围棋,甚至这样训练出的模型,比喂人类棋谱的 AlphaGo 更强大。
在此之后,围棋变成了比谁更像 AI 的游戏,因为 AI 的棋力已经超越了人类的认知范围。所以,想要超越人类,必须让模型摆脱人类经验、好恶判断(哪怕是来自最强人类的经验也不行)的限制,只有这样才能让模型能够自我博弈,真正超越人类的束缚。
AlphaGo 击败李世石引发了狂热的 AI 浪潮,从 2016 到 2020 年,巨额的 AI 经费投入最终收获的成果寥寥无几。数得过来的的可能只有人脸识别、语音识别和合成、自动驾驶、对抗生成网络等——但这些都算不上超越人类的智能。
为何如此强大的超越人类的能力,却没有在其他领域大放异彩?人们发现,围棋这种规则明确、目标单一的封闭空间游戏最适合强化学习,与之类似的还有 DotA、星际争霸、王者荣耀、斗地主等。对比之下,现实世界则复杂得多:开放空间,每一步都有无限种可能,没有确定的目标(比如"赢"),没有明确的成败判定依据(比如占据棋盘更多区域),试错成本也很高,自动驾驶一旦出错后果严重。
AI 领域冷寂了下来,直到 ChatGPT 的出现。
ChatGPT 改变世界
ChatGPT 被 The New Yorker 称为网络世界的模糊照片(ChatGPT Is a Blurry JPEG of the Web),它所做的只是把整个互联网的文本数据送进一个模型,然后预测下一个字是什_
这个字最有可能是"么"。
一个参数量有限的模型,被迫学习几乎无限的知识:过去几百年不同语言的书籍、过去几十年互联网上产生的文字,所以它其实是在做信息压缩:将不同语言记载的相同的人类智慧、历史事件和天文地理浓缩在一个模型里。
科学家惊讶地发现:在压缩中产生了智能。
我们可以这么理解:让模型读一本推理小说,小说的结尾"凶手是_“,如果 AI 能准确预测凶手的姓名,我们有理由相信它读懂了整个故事,即它拥有"智能”,而不是单纯的文字拼贴或死记硬背。
让模型学习并预测下一个字的过程,被称之为预训练(Pre-Training),此时的模型只能不断预测下一个字,但不能回答你的问题,要实现 ChatGPT 那样的问答,需要进行第二阶段的训练,我们称之为监督微调(Supervised Fine-Tuning, SFT),此时需要人为构建一批问答数据,例如:
人类:第二次世界大战发生在什么时候?
AI:1939年
人类:请总结下面这段话....{xxx}
AI:好的,以下是总结:xxx
值得注意的是,以上这些例子是人工构造的,目的是让 AI 学习人类的问答模式,这样当你说"请翻译这句:xxx"时,送给 AI 的内容就是
你看,它其实仍然在预测下一个字,在这个过程中模型并没有变得更聪明,它只是学会了人类的问答模式,听懂了你在要求它做什么。
这还不够,因为模型输出的回答有时好、有时差,有些回答还涉及种族歧视、或违反人类伦理(“如何抢银行?”),此时我们需要找一批人,针对模型输出的几千条数据进行标注:给好的回答打高分、给违反伦理的回答打负分,最终我们可以用这批标注数据训练一个奖励模型,它能判断模型输出的回答是否符合人类偏好。
我们用这个奖励模型来继续训练大模型,让模型输出的回答更符合人类偏好,这个过程被称为通过人类反馈的强化学习(RLHF)。
总结一下:让模型在预测下一个字的过程中产生智能,然后通过监督微调来让模型学会人类的问答模式,最后通过 RLHF 来让模型输出符合人类偏好的回答。
这就是 ChatGPT 的大致思路。
大模型撞墙
OpenAI 的科学家们是最早坚信压缩即智能的那批人,他们认为只要使用更海量优质的数据、在更庞大的 GPU 集群上训练更大参数量的模型,就能产生更大的智能,ChatGPT 就是在这样的信仰之下诞生的。Google 虽然做出了 Transformer,但他们无法进行创业公司那样的豪赌。
DeepSeek V3 和 ChatGPT 做的事差不多,因为美国 GPU 出口管制,聪明的研究者被迫使用了更高效的训练技巧(MoE/FP8),他们也拥有顶尖的基础设施团队,最终只用了 550 万美元就训练了比肩 GPT-4o 的模型,后者的训练成本超过 1 亿美元。
但本文重点是 R1。
这里想说的是,人类产生的数据在 2024 年底已经被消耗殆尽了,模型的尺寸可以随着 GPU 集群的增加,轻易扩大 10 倍甚至 100 倍,但人类每一年产生的新数据,相比现有的几十年、过去几百年的数据来说,增量几乎可以忽略不计。而按照 Chinchilla 扩展定律(Scaling Laws):每增加一倍模型大小,训练数据的数量也应增加一倍。
这就导致了预训练撞墙的事实:模型体积虽然增加了 10 倍,但我们已经无法获得比现在多 10 倍的高质量数据了。GPT-5 迟迟不发布、国产大模型厂商不做预训练的传闻,都和这个问题有关。
RLHF 并不是 RL
另一方面,基于人类偏好的强化学习(RLHF)最大的问题是:普通人类的智商已经不足以评估模型结果了。在 ChatGPT 时代,AI 的智商低于普通人,所以 OpenAI 可以请大量廉价劳动力,对 AI 的输出结果进行评测:好/中/差,但很快随着 GPT-4o/Claude 3.5 Sonnet 的诞生,大模型的智商已经超越了普通人,只有专家级别的标注人员,才有可能帮助模型提升。
且不说聘请专家的成本,那专家之后呢?终究有一天,最顶尖的专家也无法评估模型结果了,AI 就超越人类了吗?并不是。AlphaGo 对李世石下出第 19 手棋,从人类偏好来看,这步棋绝不可能赢,所以如果让李世石来做人类反馈(Human Feedback, HF)评价 AI 的这步棋,他很可能也会给出负分。这样,AI 就永远无法逃出人类思维的枷锁。
你可以把 AI 想象成一个学生,给他打分的人从高中老师变成了大学教授,学生的水平会变高,但几乎不可能超越教授。RLHF 本质上是一种讨好人类的训练方式,它让模型输出符合人类偏好,但同时它扼杀了超越人类的可能性。
关于 RLHF 和 RL,最近 Andrej Karpathy 也发表了类似的看法:
AI 和儿童一样,有两种学习模式。1)通过模仿专家玩家来学习(观察并重复,即预训练,监督微调),2)通过不断试错和强化学习来赢得比赛,我最喜欢的简单例子是 AlphaGo。
几乎每一个深度学习的惊人结果,以及所有魔法的来源总是 2。强化学习(RL)很强大,但强化学习与人类反馈(RLHF)并不相同,RLHF 不是 RL。
附上我之前的一条想法:

OpenAI 的解法
丹尼尔·卡尼曼在《思考快与慢》里提出,人脑对待问题有两种思考模式:一类问题不经过脑子就能给出回答,也就是快思考,一类问题需要类似围棋的长考才能给出答案,也就是慢思考。
既然训练已经到头了,那可否从推理,也就是给出回答的时候,通过增加思考时间,从而让回答质量变好呢?这其实也有先例:科学家很早就发现,给模型提问时加一句:“让我们一步一步思考”(“Let’s think step by step”),可以让模型输出自己的思考过程,最终给出更好的结果,这被称为思维链(Chain-of-Thought, CoT)。
2024 年底大模型预训练撞墙后,使用强化学习(RL)来训练模型思维链成为了所有人的新共识。这种训练极大地提高了某些特定、客观可测量任务(如数学、编码)的性能。它需要从普通的预训练模型开始,在第二阶段使用强化学习训练推理思维链,这类模型被称为 Reasoning 模型,OpenAI 在 2024 年 9 月发布的 o1 模型以及随后发布的 o3 模型,都是 Reasoning 模型。
不同于 ChatGPT 和 GPT-4/4o,在 o1/o3 这类 Reasoning 模型 的训练过程中,人类反馈已经不再重要了,因为可以自动评估思考结果,从而给予奖励/惩罚。Anthropic 的 CEO 在昨天的文章中用转折点来形容这一技术路线:存在一个强大的新范式,它处于 Scaling Law 的早期。
虽然 OpenAI 并没有公布他们的强化学习算法细节,但最近 DeepSeek R1 的发布,向我们展示了一种可行的方法。
DeepSeek R1-Zero
我猜 DeepSeek 将自己的纯强化学习模型命名为 R1-Zero 也是在致敬 AlphaZero,那个通过自我对弈、不需要学习任何棋谱就能超越最强棋手的算法。
要训练慢思考模型,首先要构造质量足够好的、包含思维过程的数据,并且如果希望强化学习不依赖人类,就需要对模型的思考过程进行定量(好/坏)评估,从而给予奖励和惩罚。
正如上文所说:数学和代码这两个数据集最符合要求,数学公式的推导能通过正则表达式来验证是否正确,而代码的输出结果以通过直接在编译器上运行来检验。
举个例子,在数学课本中,我们经常看到这样的推理过程:
<思考>
设方程根为x, 两边平方得: x² = a - √(a+x)
移项得: √(a+x) = a - x²
再次平方: (a+x) = (a - x²)²
展开: a + x = a² - 2a x² + x⁴
整理: x⁴ - 2a x² - x + (a² - a) = 0
</思考>
<回答>x⁴ - 2a x² - x + (a² - a) = 0</回答>
上面这段文本就包含了一个完整的思维链,在训练强化学习(RL)时,R1 并没有显式地对思维链的每一步进行奖励和惩罚(这也被称为过程奖励模型, PRM),而是选择只对结果进行奖励(ORM),也就是只要结果对了、有思考过程就得分,思考的内容是什么并不重要。
DeepSeek 团队发现,对过程奖励可能的问题是:思考过程到底分几步?这个数值对不同复杂度的任务是不同的。同时,每一步的正确性很难量化,有些错误的思考常常会启发模型往最终正确的方向走,而且,如果给思考过程打分,模型可能会只专注于生成正确的过程而不顾结果(reward hacking),就像考试时先把公式列出来得分,这对让模型学习如何解题反而是有害的。
而像 AlphaGo 那样使用蒙特卡洛树搜索(MCTS)的问题类似:围棋的状态空间虽然很大,但每一步的走法是有限、可枚举的,而大模型的推理思考过程是开放、无限的。和 PRM 类似,使用 MCTS 训练大模型也很难评估思考过程每一步的正确性。
除了只对结果进行奖励,研究人员还创造了一种名为GRPO(组相对策略优化)的强化学习算法,给包含思维链、且结果正确的输出打高分,从而隐式鼓励模型形成思维链。
这个帖子用一个很好的例子解释了 GRPO 的原理,我翻译一下:让模型同时生成多个回答,计算每个回答的得分,组内对比出有相对优势的回答,对模型进行 RL 训练,使其倾向于得分更高的回答。
以问题$2+3=?$为例
第一步: 模型生成多个回答:
- “5”
- “6”
- “<思考>2+3=5</思考><结果>5</结果>”
第二步: 对每个回答进行打分:
- “5” → 1 分 (正确, 没有思维链)
- “6” → 0 分 (错误)
- “<思考>2+3=5</思考><结果>5</结果>” → 2 分 (正确, 有思维链)
第三步: 计算所有回答的平均得分:
- 平均得分 = (1 + 0 + 2) / 3 = 1
第四步: 将每个回答的得分与平均得分进行比较:
- “5” → 1 - 1 = 0 (与平均分相同)
- “6” → 0 - 1 = -1 (低于平均分)
- “<思考>2+3=5</思考><结果>5</结果>” → 2 - 1 = 1 (高于平均分)
第五步: 强化学习,使模型倾向于生成得分更高的回答,也就是包含思维链、且结果正确。
以上就是 GRPO 的大致原理。
他们基于 V3 模型,在数学和代码这两类数据上用 GRPO 进行 RL 训练,最终得到的 R1-Zero 模型在各项推理指标上相比 DeepSeek V3 显著提升,证明仅通过 RL 就能激发模型的推理能力。
这是另一个 AlphaZero 时刻,在 R1-Zero 的训练过程,完全不依赖人类的智商、经验和偏好,仅靠 RL 去学习那些客观、可测量的人类真理,最终让推理能力远强于所有非 Reasoning 模型。
在训练过程中,他们发现一个有趣的现象:虽然并没有对输出长度进行奖励,但模型在训练过程中逐渐“自发”地输出更长的结果,这也符合常理:复杂的问题通常需要更长的思考过程才能解决。
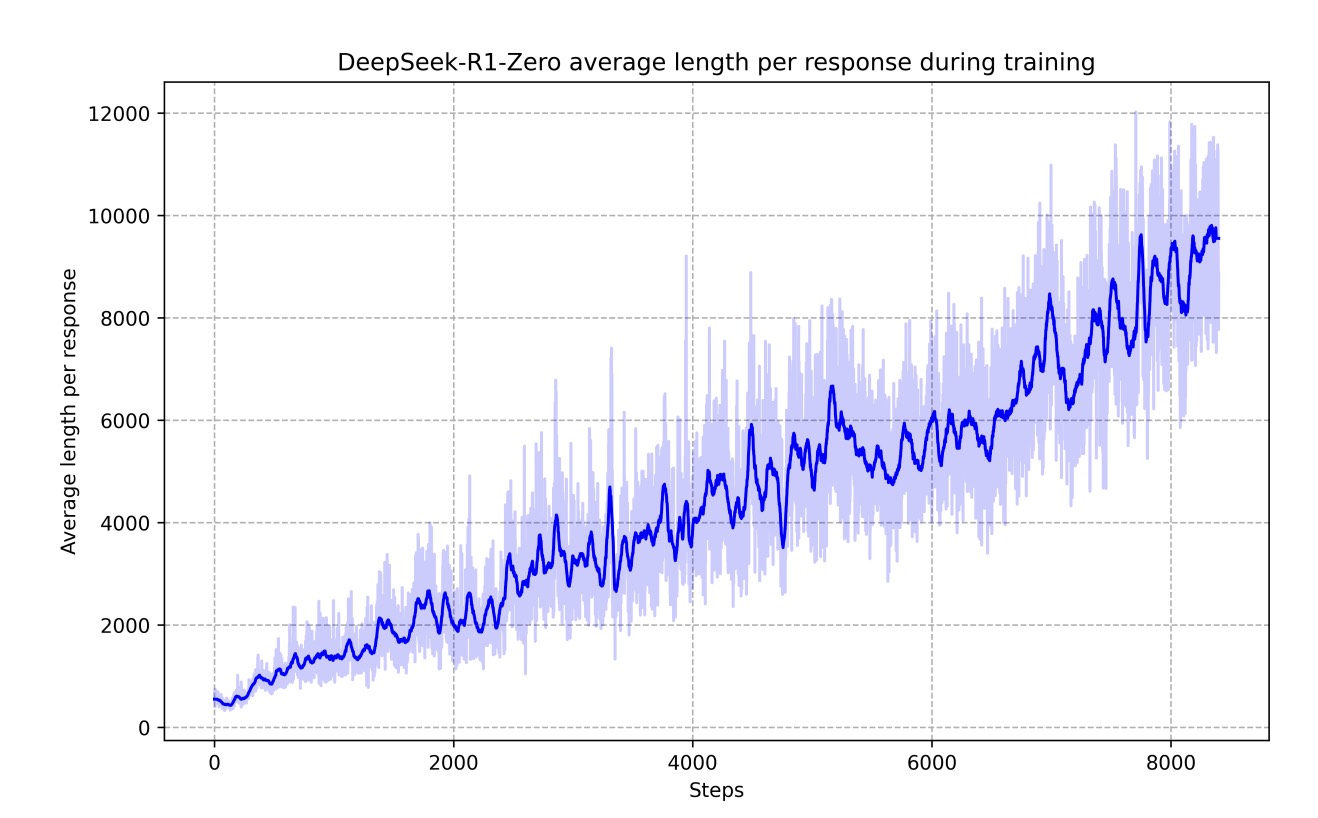
但 R1-Zero 模型只是单纯地进行强化学习,并没有进行监督学习,所以它没有学会人类的问答模式,无法回答人类的问题。并且,它在思考过程中,存在语言混合问题,一会儿说英语、一会儿说中文,可读性差。所以 DeepSeek 团队:
- 先收集了少量高质量的 Chain-of-Thought(CoT)数据,对 V3 模型进行初步的监督学习(SFT),解决了输出语言不一致问题,得到冷启动模型。
- 然后,他们在这个冷启动模型上进行类似 R1-Zero 的纯 RL 训练,并加入语言一致性奖励,此时的模型推理能力大幅增强,语言一致性问题也得以改善。
- 接着,为了适应更普遍、广泛的非推理任务(如写作、事实问答),他们构造了一组数据对模型进行二次训练。因为写作这类任务的模型输出好坏很难评估,所以他们没有使用 RL 训练,而是使用监督学习(SFT)。
- 最后,同时训练推理和通用任务数据,目的是移除无用或者有害的思考过程,同时保持推理能力。对于推理任务,他们遵循 R1-Zero 的 RL 训练方式,对于写作任务,他们从 DeepSeek V3、R1-Zero 生成的数据中,挑选出人类偏好的结果作为奖励进行训练(类似 RLHF)。
这个过程大概就是:
监督学习 - 强化学习 - 监督学习 - 强化学习
经过以上过程,就得到了 DeepSeek R1。
DeepSeek R1 给世界的贡献是开源世界上第一个比肩闭源(o1)的 Reasoning 模型,现在全世界的用户都可以看到模型在回答问题前的推理过程,也就是"内心独白",并且完全免费。
更重要的是,它向研究者们揭示了 OpenAI 一直在隐藏的秘密:强化学习可以不依赖人类反馈,纯 RL 也能训练出最强的 Reasoning 模型。所以在我心目中,R1-Zero 比 R1 更有意义。
对齐人类品味 VS 超越人类
几个月前,我读了 Suno 和 Recraft 创始人们的访谈,Suno 试图让 AI 生成的音乐更悦耳动听,Recraft 试图让 AI 生成的图像更美、更有艺术感。读完后我有一个朦胧的感觉:将模型对齐到人类品味而非客观真理,似乎就能避开真正残酷的、性能可量化的大模型竞技场。
每天跟所有对手在 AIME、SWE-bench 这些榜单上竞争多累啊,而且不知道哪天一个新模型出来自己就落后了(你还记得 Mistral 吗?),但人类品味就像时尚:不会提升、只会改变。Suno/Recraft 们显然是明智的,他们只要让行业内最有品味的音乐人和艺术家们满意(当然这也很难),榜单并不重要。
对齐人类品味的坏处也很明显:你的努力和心血带来的效果提升也很难被量化,比如,Suno V4 真的比 V3.5 更好吗?我的经验是 V4 只是音质提升了,创造力并没有提升。并且,依赖人类品味的模型注定无法超越人类:如果 AI 推导出一个超越当代人类理解范围的数学定理,它会被奉为上帝,但如果 Suno 创造出一首人类品味和理解范围外的音乐,在普通人耳朵里听起来可能就只是单纯的噪音。
对齐客观真理的竞争痛苦但让人神往,因为它有超越人类的可能。
对质疑的一些反驳
DeepSeek 的 R1 模型,是否真的超越了 OpenAI?
从指标上看,R1 的推理能力超越了所有的非 Reasoning 模型,也就是 ChatGPT/GPT-4/4o 和 Claude 3.5 Sonnet,与同为 Reasoning 模型 的 o1接近,逊色于 o3,但 o1/o3 都是闭源模型。
很多人的实际体验可能不同,因为 Claude 3.5 Sonnet 在对用户意图理解上更胜一筹。
DeepSeek 会收集用户聊天内容用于训练
很多人有个误区,认为类似 ChatGPT 这类聊天软件会通过收集用户聊天内容用于训练而变得更聪明,其实不然,如果真是这样,那么微信和 Messenger 就能做出世界上最强的大模型了。
相信你看完这篇文章之后就能意识到:大部分普通用户的日常聊天数据已经不重要了。RL 模型只需要在非常高质量的、包含思维链的推理数据上进行训练,例如数学和代码。这些数据可以通过模型自己生成,无需人类标注。因此 做模型数据标注的公司 Scale AI 的 CEO Alexandr Wang 现在很可能正如临大敌,未来的模型对人类标注需求会越来越少。
更新:ARC-AGI 的这篇分析 r1-zero 的文章暗示了一个新想法,未来的 Reasoning 模型可以收集用户和模型聊天时 AI 生成的思维链来训练——和人们假想的 AI 偷偷用聊天记录训练不同,用户说了什么其实不重要,在他们付费得到结果的同时,模型 0 成本增加了一条推理思维链数据。
DeepSeek R1 厉害是因为偷偷蒸馏了 OpenAI 的模型
R1 最主要的性能提升来自强化学习,你可以看到纯 RL、不需要监督数据的 R1-Zero 模型在推理能力上也很强。而 R1 在冷启动时使用了一些监督学习数据,主要是用于解决语言一致性问题,这些数据并不会提升模型的推理能力。
另外,很多人对蒸馏有误解:蒸馏通常是指用一个强大的模型作为老师(Teacher),将它的输出结果用于指导一个参数更小、性能更差的学生(Student)模型,让学生模型直接背答案变得更强,例如 R1 模型可以用于蒸馏 LLama-70B,蒸馏的学生模型性能几乎一定比老师模型更差,但 R1 模型在某些指标性能比 o1 更强,所以说 R1 的性能源于蒸馏 o1 是非常愚蠢的。
我问 DeepSeek 它 说自己是 OpenAI 的模型,所以它是套壳的。
大模型在训练时并不知道当前的时间,自己究竟被谁训练、训练自己的机器是 H100 还是 H800,DeepSeek 之所以会回答自己是 ChatGPT,是因为它的训练数据中包含"我是 ChatGPT"之类的语料。X 上有位用户给出了精妙的比喻:这就像你问一个 Uber 乘客,他坐的这辆车轮胎是什么品牌,模型没有理由知道这些信息。
一些感受
AI 终于除掉了人类反馈的枷锁。DeepSeek R1-Zero 展示了如何使用几乎不使用人类反馈来提升模型性能的方法,这是它的 AlphaZero 时刻。很多人曾说"人工智能,有多少人工就有多少智能",这个观点可能不再正确了。如果模型能根据直角三角形推导出勾股定理,我们有理由相信它终有一天,能推导出现有数学家尚未发现的定理。
写代码是否仍然有意义?我不知道。今早看到 Github 上热门项目 llama.cpp,一个代码共享者提交了 PR,表示他通过对 SIMD 指令加速,将 WASM 运行速度提升 2 倍,而其中 99%的代码由 DeepSeek R1 完成,这肯定不是初级工程师级别的代码了,我无法再说 AI 只能取代初级程序员。
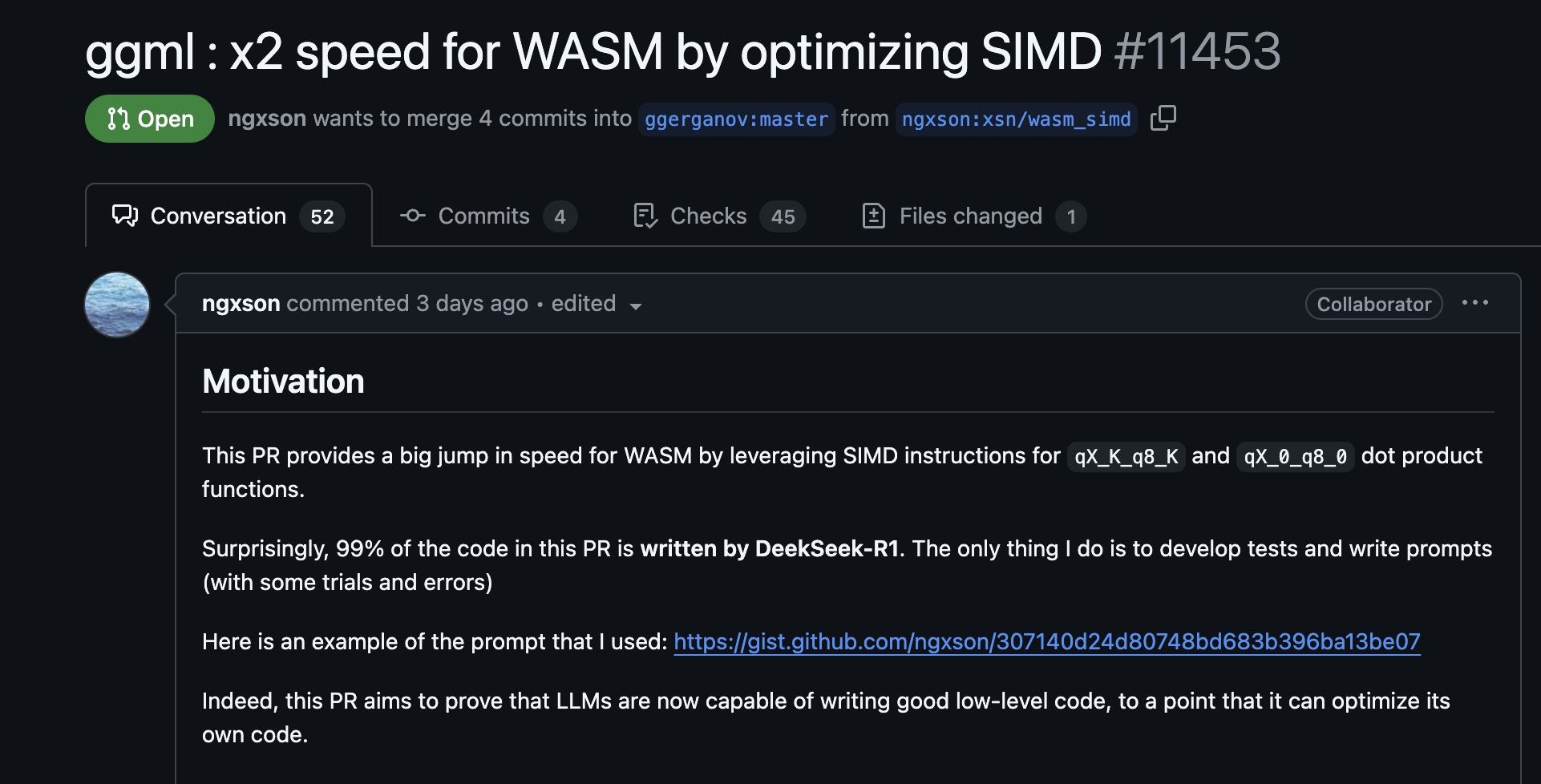
当然,我仍然对此感到非常高兴,人类的能力边界再次被拓展了,干得好 DeepSeek!它是目前世界上最酷的公司。
参考资料